Finding expired domains to leverage their value is one of the most popular SEO strategy over the last few years.
It is being as popular as it is highly effective. And by being popular it is quite difficult to find suitable domains for such purposes since every Digital Marketers is after such domains and most of them are looking at the same sources.
One of such source is being the website: https://www.expireddomains.net/
While it is a great website, most of the good expired domains are taken immediately and you’ll end up finding more likely penalised domains which will do more harm than good to your website and to your wallet.
This article will describe an endless source of targeted qualitative expired domains which you can easily set for your online businesses.
What makes an expired domain good?
The most obvious answer is the backlink profile. By registering back an expired domain, you’ll benefit from the past backlinks it used to have and of course the stronger the backlinks the stronger your domain will be for your own SEO campaigns.
That being said, there is another factor which is often being overlooked since it sounds difficult and unbearable to achieve and yet it is far more effective: A niche targeted backlink profile.
Let’s dive in a nutshell into some Search Engines Indexing basics:
A Search Engine relies on an indexer working with Ngrams (group of words to define concepts – Google can go up to 8 words to define a concept which is tremendous). Its goal is to dress a semantic map of a content with all the concepts quoted. If we were to set a human readable diagram for the semantic content indexing, it would look something like this:
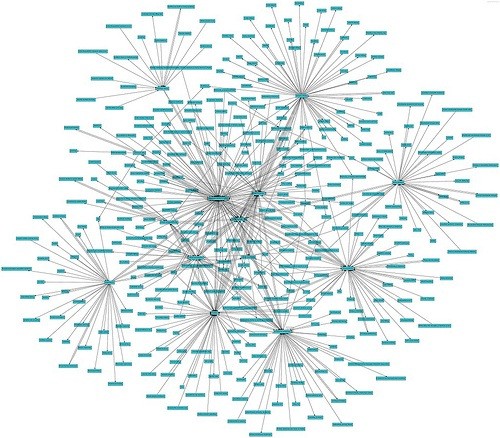
In this diagram, you can see some nodes and some subsidiary concepts emphasizing the node which allows Google to compare the content between one website and another dealing with the same subject. With the amount of data gathered, they are able to expect associated concepts to a core one in order to assess the content quality. But they mainly meant to be able to make distinction about similar concepts and refine the results they would give for a query. For instance, if you were to make an article on flowers. You can write about the plants or sell flowers. The associated concepts to the word flowers will help define what your website is among the slight semantic differences.
Now, for website rankings, Google has to make the distinction between a good content and a lesser content and it relies on around 200 metrics.
Among these 200, the most powerful metric is backlinks.
A backlink is structural to the web and it basically implies if a given website link to another it means that the linked website is the referral for a given topic.
Let’s take the example of this article. It will rank for a set of queries involving expired domains, however it is highly likely that expireddomains.net will be shown before this article since there is a link to it. Now, this article will remain before expired domains.net website for all semantic indexing related queries since the website isn’t talking about it.
But Google is smart, very smart. It will indeed analyse the authority of the website producing the outgoing link which would make the backlink credible or not but it will also give a semantic relevancy score to the link which would basically tell whether it is natural or not. The anchors are one way to get a semantic concept out of a link but also nowadays the wrapping context around the backlink. With your flowers websites, if you have links coming from a hair dryer based website, it doesn’t make any remote semantic sense. While it may occur at occasion it isn’t natural. On the other hand there is Wikipedia, which is dominating the search results. The reason is that they have a semantic rich content around a topic and many websites covering such topics are making links to them.
And there you go.
Now you understand that finding high authority domains is indeed powerful but if you have high authority domain semantically relevant to your websites, it is far more powerful.
How to find Expired Domains Sources?
This is where the core idea of this method is being exposed.
We have seen that finding authority domain is great for SEO but finding niche related high authority domains is giving far better results.
The issue here is that if you are seeking for expired domains lists odds are you’ll be paying premium for these domains.
You’ll just need to find the authority website in your niche. It can be Wikipedia, a massive website or even a website with the backlink you want.
For this step you would just need to compute a list of authority websites in your niche or high authority websites you would like a backlink from for your network.
From there you will be set to proceed with this method to find expired domains.
The method.
The method relies on the king of the SEO Tool: Scrapebox.
- Choose the website you would like to get back link from. It can be a competitor (for semantic based backlink) or any authority website. For the method here we will be opting for Wikipedia.
Wikipedia remains a great source as the issue to obtain a backlink from Wikipedia is to get a backlink that stick through time. You may therefore get an instant backlink from Wikipedia that is likely to remain since the domain was initially expired. - Once you have your website, open Scrapebox and in the ‘Harvester and Keywords’ Section, you may set the following:
site:wikipedia.org
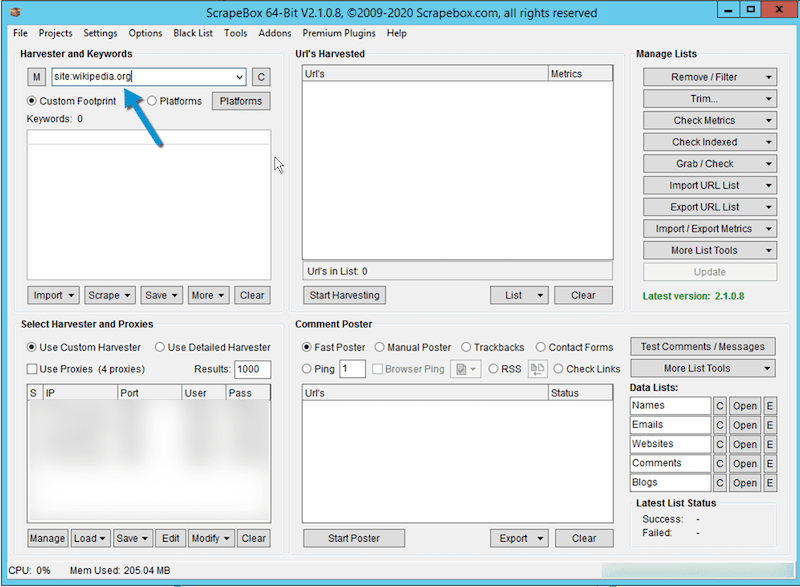
And click on “Start Harvesting” to open the harvester window.
Once the Harvester windows is opened, you may select Bing & Google. And click “Start”. The number of URL In the seed scrape isn’t important as you’ll see below.
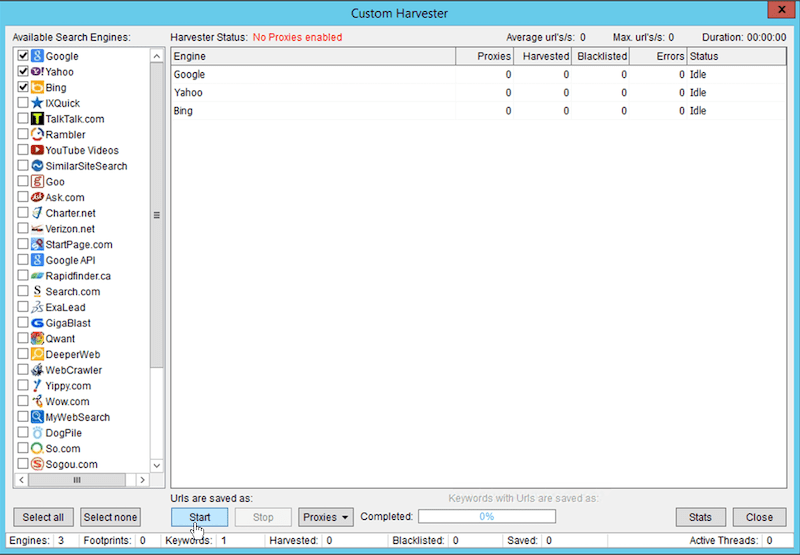
Once the first set of data for the internal link is completed, you may import this list into your Scrapebox harvester and launch back the Scrapebox Link Extractor. You may also filter the list if you need a specific string in the URL. For wikipedia, for instance you may want to keep only “en.” URL so you have English only URLs. To do so, in the Scrapebox main view, click on “Remove / Filter” and select “Remove URL Not Containing” and set the string you would like to filter from.
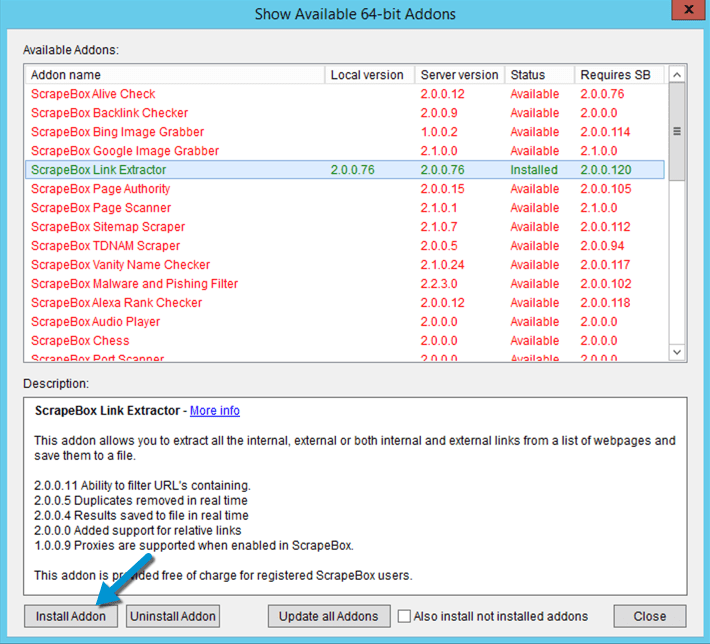
If you haven’t yet installed the Scrapebox plugin, you would need in the main Scrapebox view to click on “Addons”, and then on “Show Available Addons”. From the list, highlight the plugin ScrapeBox Link Extractor and click on “Install Addon”.
Launch the Add-on Windows and click on “Load” then on “Load URL from the Harvester”. You should see something like the screenshot below. You need to select “Internal” at the bottom and then click on “Start”. 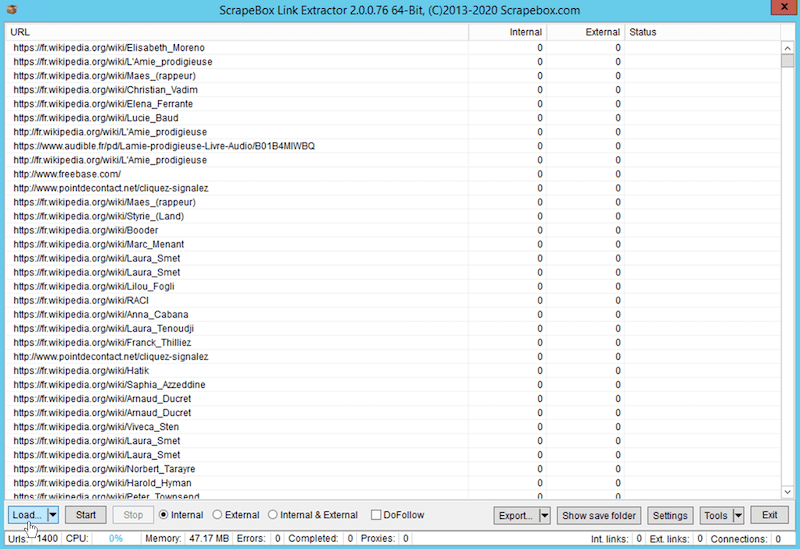
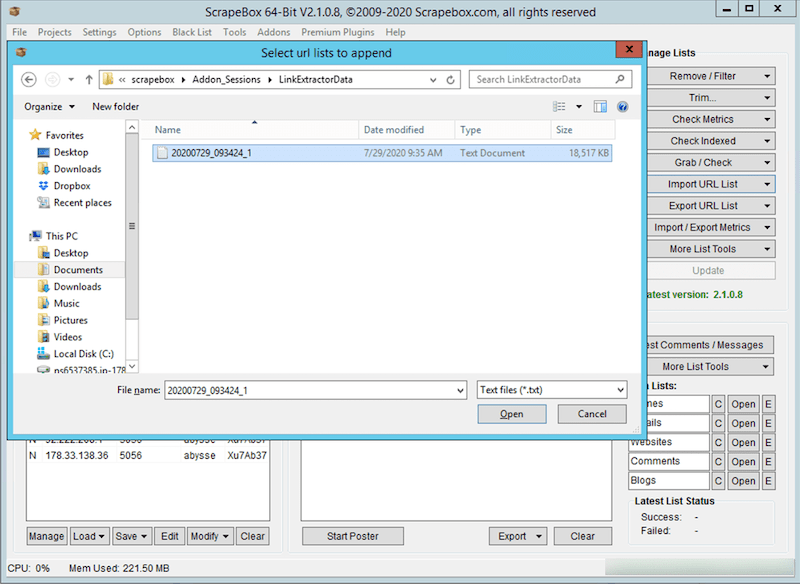
Once completed, you have grown significantly the number of internal URL of your website. You may click on the Main Scrapebox window and click on “Import URL List”, “Import and Add to the Current List” and select the list you built from the add-on. It is located in:
.ScrapeboxFolder\Addon_Sessions\LinkExtractorData
Select it as indicated below:
You may click on “Remove / Filter” and “Remove Duplicates URL” to curate your main list of internal URL.
From this point, you have a list of Internal URL which you may grow for as much as you like. In which case, you just need to repeat the last step and load the harvester URL onto the add-on and initiate another Internal URL scrape.
From a SERPS scrape and a one time Internal Linking Scrape on Wikipedia, I obtained around 40 000 URLS to check for external domains which I import back to Scrapebox main harvester. IF I was to add another Intnernal linking scrapping, I would end up with having over a few millions URL to check backlink from. Of course, you can refine this to your liking to target your backlinks further. It is the killer feature of this method as you can as precise as you want for your backlinks to obtain the greater results.
Now, we can launch back the Scrapebox Link Extractor except that you would simply need to change the option to scrape only “External”. We hit the “Start” button
and it will fetch all outbound links from all the pages.
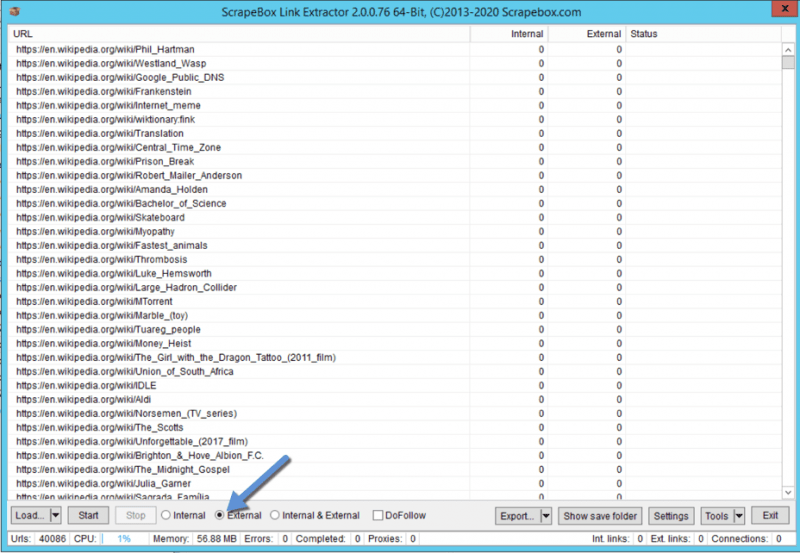
Let Scrapebox for as long as it needs and come back to your Link Extractor folder data:
..ScrapeboxFolder\Addon_Sessions\LinkExtractorData
And import the list of external domains into your Scrapebox Harvester. (it is a good practice to export and save your previous website internal URLs).
Once it is loaded, click on the “Trim Menu” and select “Trim to Root” which will have for effect to only keep the domain name. Then, click on “Remove / Filter” and “Duplicated Domain”. So you’ll end up with an unique list of domains with a backlink from the website you want.
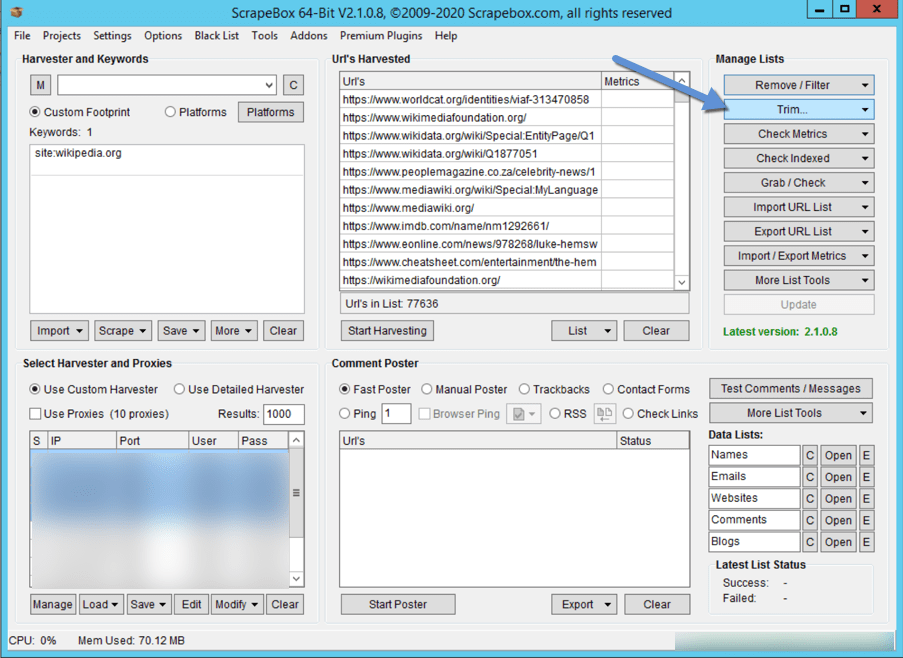
Now, you have a lot of free domain at your disposal which you may register right away. You can then choose to 301 them to your domain or to set them as part of your PBN. In which case, I couldn’t recommend you enough to check the SEO hosting offers from HostStage directly.
This method takes work but I was able to redirect SEO Juice from competitors and outrank them or get untapped expired domains for my PBN.